算法可视化:
数据结构和算法动态可视化 (Chinese) - VisuAlgo
Data Structure Visualization (usfca.edu)
数据结构和算法:(图文解析)Hello 算法 (hello-algo.com) (github项目源码地址:krahets/hello-algo: 《Hello 算法》:动画图解、一键运行的数据结构与算法教程,支持 Java, C++, Python, Go, JS, TS, C#, Swift, Rust, Dart, Zig 等语言。 (github.com))
c++中没有split库函数,我们可以自己封装一个
这里我们会用到一个c++的库函数strtok()
| 函数原型 |
char * strtok(char *s, const char *delim) |
| 函数功能 |
分解字符串为一组字符串, s为要分解的字符串,delim为分隔字符串 |
| 描述 |
strtok()用来将字符串分隔成一个个小片段,参数s指向将要被分隔的字符串,参数delim则为分隔字符串,当strtok()在参数s的字符串中发现到参数delim的分隔符时,则会将该字符串改为 ‘\0’ 字符,在第一次调用时,strtok()必须给予参数s字符串,往后的调用则将参数s设置成NULL。每次调用成功则返回被分隔 片段的指针。 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| vector<string> split(const string& str, const string& delim) {
vector<string> res;
if("" == str) return res;
char * strs = new char[str.length() + 1];
strcpy(strs, str.c_str());
char * d = new char[delim.length() + 1];
strcpy(d, delim.c_str());
char * p = strtok(strs, d);
while(p) {
string s = p;
res.push_back(s);
p = strtok(NULL, d);
}
return res;
}
|
排序算法:
直接插入排序:(稳定)
时间复杂度:O(n^2)
存放待排序序列的数组的第一个位置不存储数据,该位置作为哨兵位,暂存我们正在处理的那个元素的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| #include<iostream>
using namespace std;
int main()
{
int k;
int *L;
int listsize,i,j;
cout<<"请输入listsize的值=";
cin>>listsize;
L=new int[listsize+1];
for(i=1;i<=listsize;i++)
cin>>L[i];
for(i=2;i<=listsize;i++) {
if(L[i]<L[i-1]){
L[0]=L[i];
j=i;
while(L[j - 1] > L[0]) {
L[j] = L[j - 1];
j--;
}
L[j] = L[0];
}
for(k=1;k<=listsize;k++)
cout<<L[k]<<" ";
cout<<endl;
}
cout << "最终的结果:";
for(i=1;i<=listsize;i++)
cout<<L[i]<<" ";
return 0;
}
|
折半插入排序:(稳定)
时间复杂度:O(n^2)
这里我们用到了二分查找(折半查找),来确定需要插入的位置。
注意:二分查找只适用于有序序列的查找,而且对于升序序列和降序序列的二分查找函数的写法是不一样的
这里我们使用的是升序序列的二分查找
存放待排序序列的数组的第一个位置不存储数据,该位置作为哨兵位,暂存我们正在处理的那个元素的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| #include<iostream>
#include<vector>
using namespace std;
void display(vector<int> v) {
for(int i = 1; i < v.size(); i++) {
cout << v[i] << " ";
}cout << endl;
}
void Binary_Insertion_Sort(vector<int>& v) {
int low, high;
for(int i = 2; i < v.size(); i++) {
if(v[i] < v[i - 1]) {
v[0] = v[i];
low = 1; high = i - 1;
while(low <= high) {
int mid = (low + high) / 2;
if(v[0] > v[mid]) {
low = mid + 1;
}else {
high = mid - 1;
}
}
for(int j = i - 1; j >= low; --j) {
v[j + 1] = v[j];
}
v[low] = v[0];
}
cout << "第" << i - 1 <<"趟排序:";
display(v);
}
}
int main() {
int n;
cout << "请输入元素的个数:";
cin >> n;
vector<int> v(n + 1);
cout << "请输入待排序序列:";
for(int i = 1; i <= n; i++) {
cin >> v[i];
}
Binary_Insertion_Sort(v);
}
|
希尔排序:(不稳定)
时间复杂度:O(n^1.3)
存放待排序序列的数组的第一个位置不存储数据,该位置作为哨兵位,暂存我们正在处理的那个元素的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| #include<iostream>
#include<vector>
using namespace std;
void display(vector<int> v) {
for(int i = 1; i < v.size(); i++) {
cout << v[i] << " ";
}cout << endl;
}
void ShellSort(vector<int>& v, int n) {
int dk, i, j;int cnt = 1;
for(dk = n/2; dk >= 1; dk /= 2) {
for(i = 1 + dk; i <= n; i++) {
if(v[i] < v[i - dk]) {
v[0] = v[i];
j = i;
while(j - dk >= 0 && v[j - dk] > v[0]) {
v[j] = v[j - dk];
j -= dk;
}
v[j] = v[0];
}
}
cout << "第" << cnt++ <<"趟排序:";
display(v);
}
}
int main() {
int n;
cout << "请输入元素的个数:";
cin >> n;
vector<int> v(n + 1);
cout << "请输入待排序序列:";
for(int i = 1; i <= n; i++)
cin >> v[i];
ShellSort(v, n);
return 0;
}
|
冒泡排序:(稳定)
时间复杂度:O(n^2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void bubble(vector<int> &v) {
int temp;
int n = v.size();
for(int i = 1; i < n; i++) {
bool flag = false;
for(int j = 0; j < n - i; j++) {
if(v[j] > v[j + 1]) {
temp = v[j];
v[j] = v[j + 1];
v[j + 1] = temp;
flag = true;
}
}
if(flag == false) {
return;
}
}
}
|
快速排序:(不稳定)(最常使用,效率相对较好)
时间复杂度 = O(n * 递归层数) = O(nlog2n)
空间复杂度 = O(递归层数) = O(log2n)
递归层数可以转化为二叉树的高度(log2n ~ n)(最高 ~ 最矮) n为结点个数
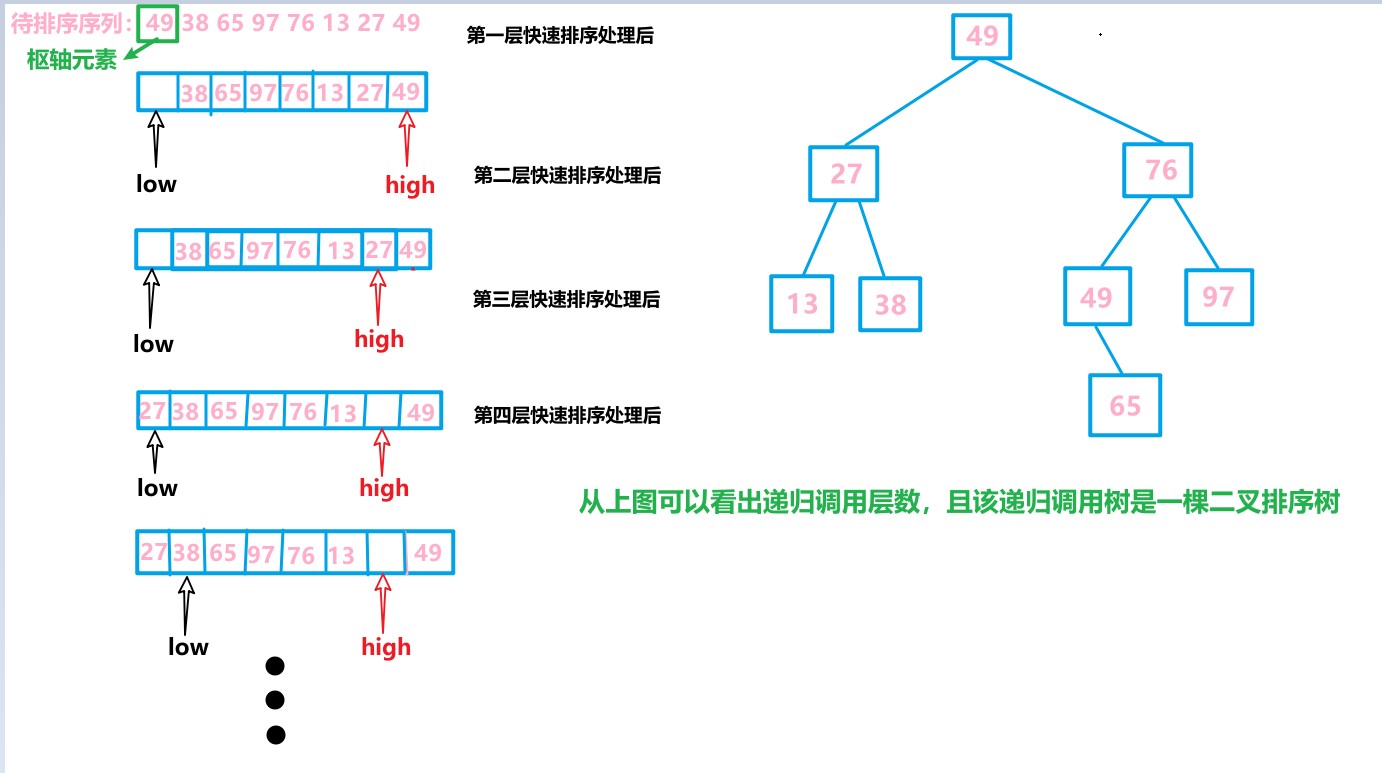
快速排序在处理有序序列的排序时效率是最低的。若每一次选中的枢轴元素将待排序序列划分为很不均匀的两个部分,则会导致递归深度增加,算法效率变低
快速排序算法优化思路:尽量选择可以把数据 中分的 枢轴元素
例如:1、选头、中、尾三个位置的元素,取中间值作为枢轴元素
2、随机选一个元素作为枢轴元素
算法思路:先确定一个枢轴元素,将这个位置的值用一个变量记录下来,然后用两个指针low和high分别指向待排序序列的头和尾,先从high指针往前判断,如果high指针所指向的元素小于枢轴元素,那么就将该元素放到low指针所指向的位置,然后再从low指针往后判断,如果low指针所指向的元素大于枢轴元素,那么就将该元素放到high指针所指向的位置,这样就能使得low指针左边的元素都小于枢轴元素,high指针右边的元素都大于枢轴元素;然后依次循环往复,直到low==high时,即找到了枢轴元素应该放入的位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| #include<iostream>
#include<vector>
using namespace std;
int partition(vector<int> &v, int low, int high) {
int pivot = v[low];
while(low < high) {
while(low < high && v[high] >= pivot) {
--high;
}v[low] = v[high];
while(low < high && v[low] <= pivot) {
++low;
}v[high] = v[low];
}
v[low] = pivot;
return low;
}
void QuickSort(vector<int> &v, int low, int high) {
if(low < high) {
int pivotPos = partition(v, low, high);
QuickSort(v, low, pivotPos - 1);
QuickSort(v, pivotPos + 1, high);
}
}
int main() {
int n;
cout << "请输入待排序序列中元素的个数:";
cin >> n;
vector<int> v(n);
cout << "请输入待排序序列:";
for(int i = 0; i < n; i++) {
cin >> v[i];
}
QuickSort(v, 0, n - 1);
for(int i = 0; i < n; i++) {
cout << v[i] << " ";
}
return 0;
}
|
简单选择排序:(不稳定)
时间复杂度:O(n^2)
1
2
3
4
5
6
7
8
9
10
11
| void SelectSort(vector<int> v) {
for(k = 0; k < n - 1; k++) {
index = k;
for(i = k + 1; i < n; i++)
if(a[i] < a[index])
index = i;
temp = a[index];
a[index] = a[k];
a[k] = temp;
}
}
|
堆排序:(不稳定)
考研考察频率比较高
时间复杂度:O(nlog2n)
空间复杂度:O(1)
建堆时间:O(n)
建堆:( O(n) )
思路:把所有非终端结点都检查一遍,是否满足大根/小根堆的要求,如果不满足,则进行调整
可以将堆视为一棵完全二叉树
在顺序存储的完全二叉树中,非终端结点编号 i <= ⌊ n/2 ⌋
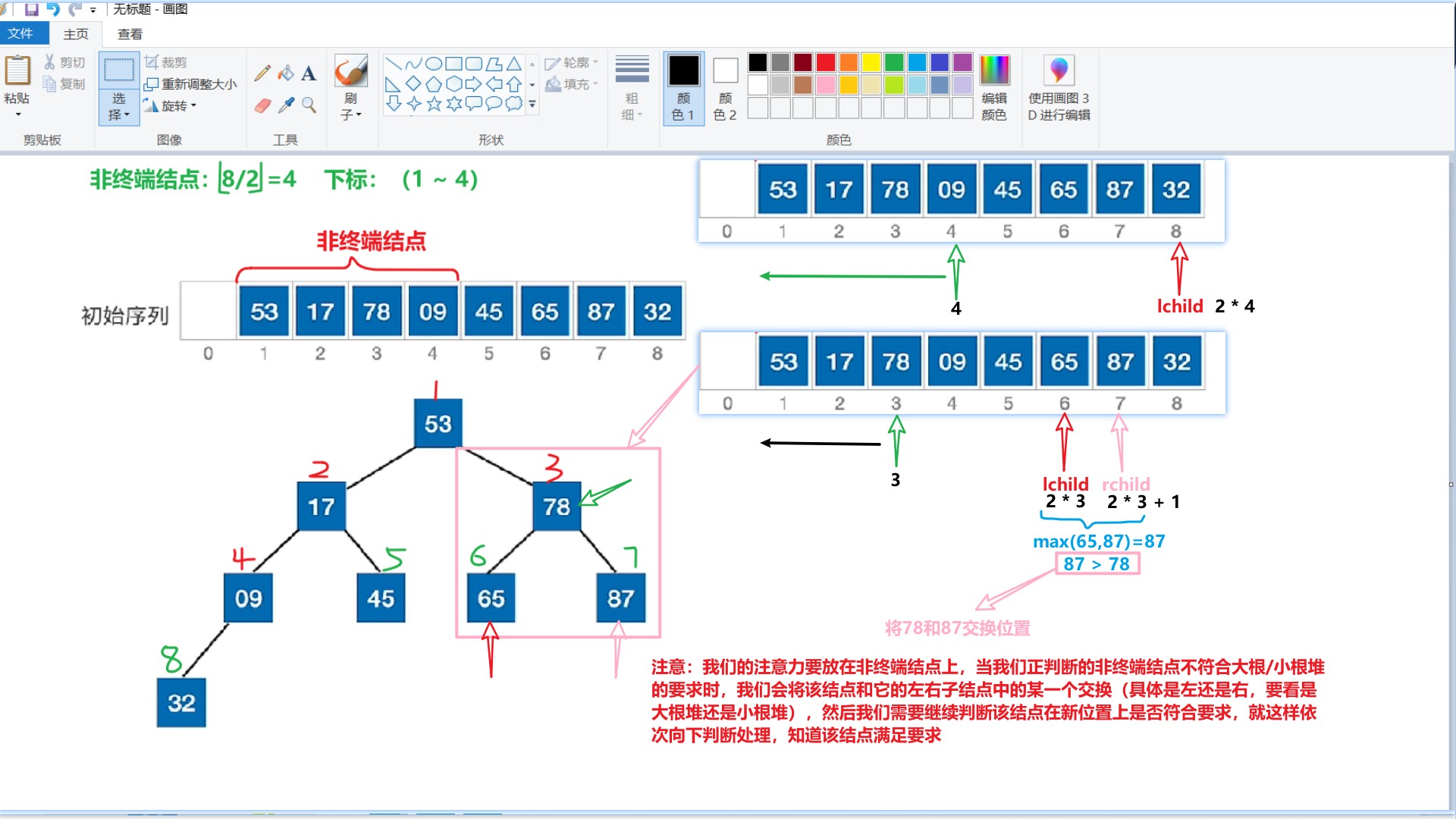
堆排序代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<iostream>
#include<vector>
using namespace std;
void HeadAdjust(vector<int> &v, int k, int len) {
for(int i = 2 * k; i <= len; i *= 2) {
if(i + 1 <= len && v[i] < v[i + 1]) {
i++;
}
if(v[k] >= v[i]) {
break;
}else {
v[0] = v[k];
v[k] = v[i];
v[i] = v[0];
k = i;
}
}
}
void BuildMaxHeap(vector<int> &v) {
int len = v.size() - 1;
for(int i = len / 2; i >= 1; i--) {
HeadAdjust(v, i, len);
}
}
void HeapSort(vector<int> &v) {
int len = v.size() - 1;
BuildMaxHeap(v);
for(int i = len; i > 1; i--) {
swap(v[i], v[1]);
HeadAdjust(v, 1, i - 1);
}
}
int main() {
int n;
cout << "请输入待排序序列中元素的个数:";
cin >> n;
vector<int> v(n + 1);
cout << "请输入待排序序列:";
for(int i = 1; i <= n; i++) {
cin >> v[i];
}
HeapSort(v);
for(int i = 1; i <= n; i++) {
cout << v[i] << " ";
}
return 0;
}
|
插入元素:对堆进行插入操作时,先将新结点放在堆的末端,再对这个新结点向上执行调整操作,即依次向上与之父结点进行比较(上升操作)
删除元素:在进行删除操作时,我们会将堆底元素换到被删除元素的位置,然后让该元素不断下坠
在向有n个元素的堆中插入一个新元素时,需要调用一个向上调整的算法,比较次数最多等于树的高度减一,由于树的高度为
⌊ log2n ⌋ + 1,所以堆的向上调整算法的比较次数最多等于⌊ log2n ⌋。
归并排序:(稳定)
空间复杂度:Merge()操作中,辅助空间刚好为n个单元,所以算法的空间复杂度为O(n)
时间复杂度:每趟归并的时间复杂度为O(n),共需要log2n趟归并,所以算法的时间复杂度为O(nlog2n)
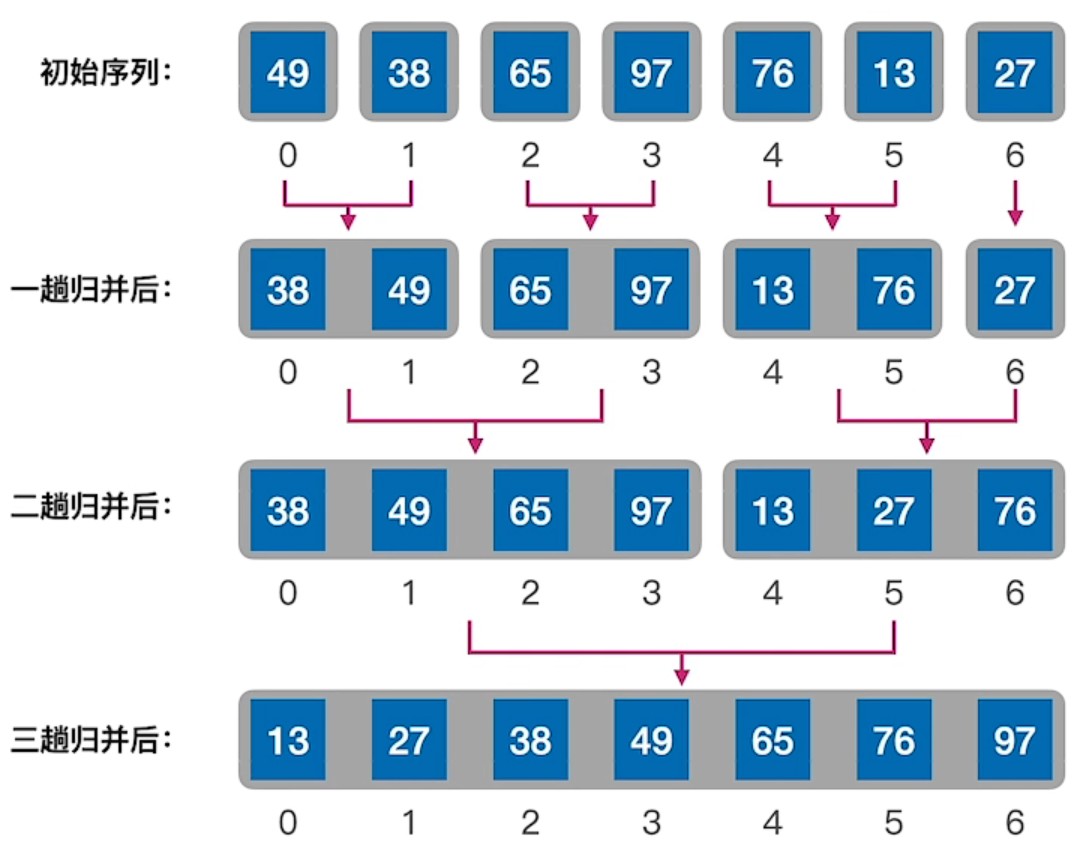
归并排序的一个核心步骤就是将两个有序的序列合并为一个有序的序列(2-路归并)
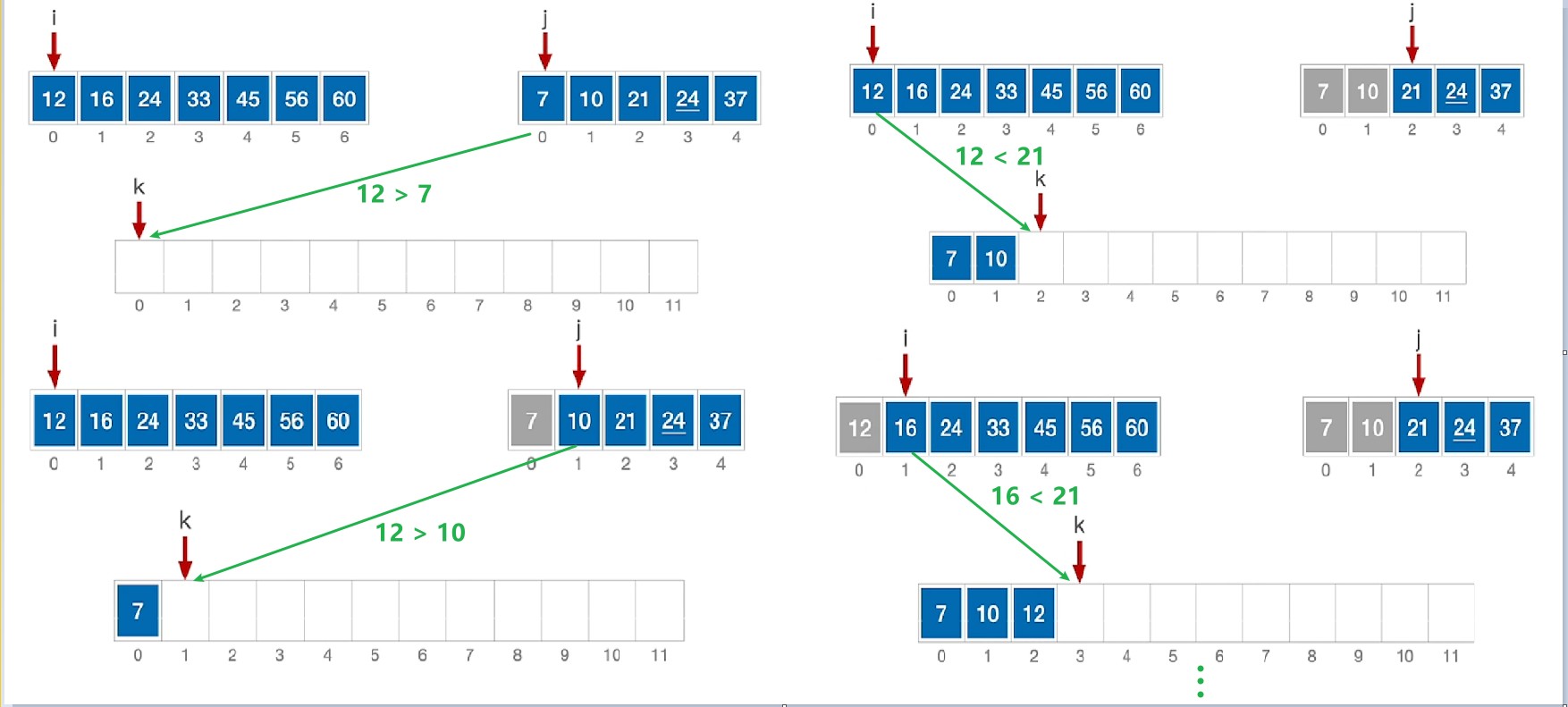
由此我们也可以推断出其他多路归并的情况
对于2路-归并排序,采用的是2路归并
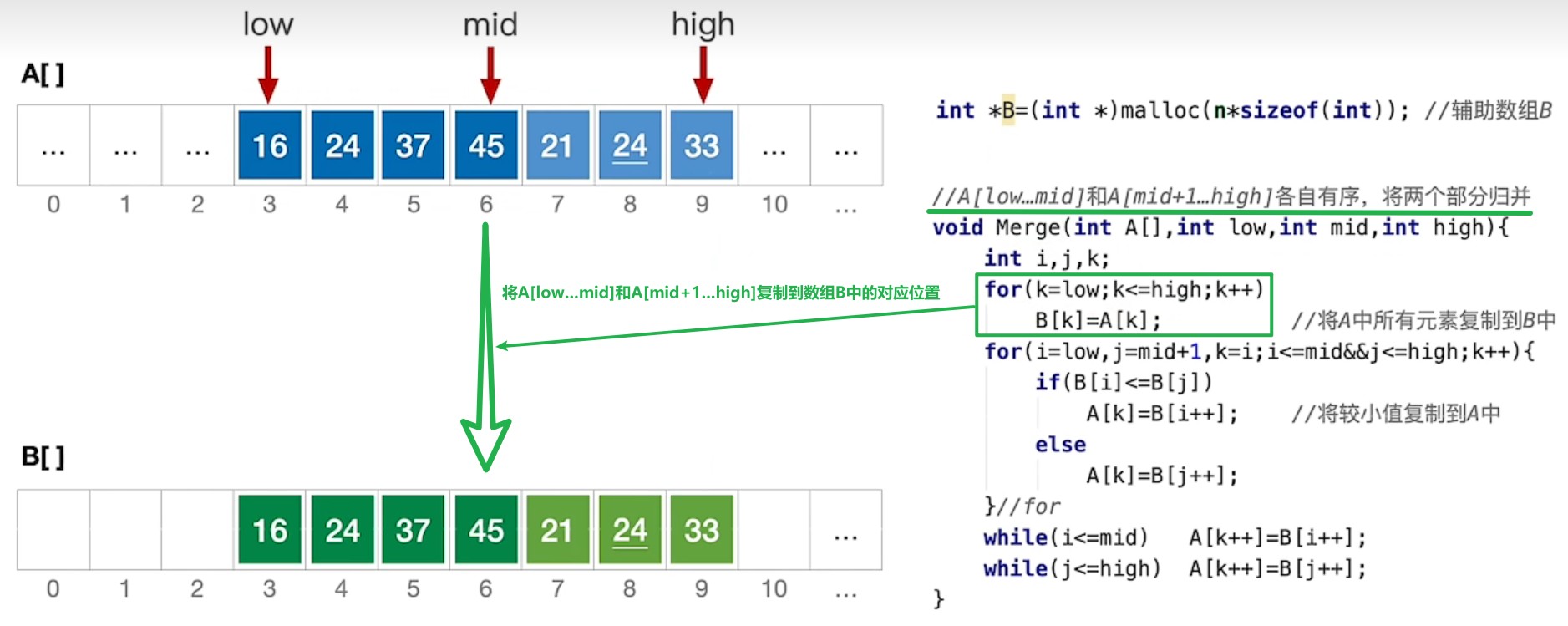
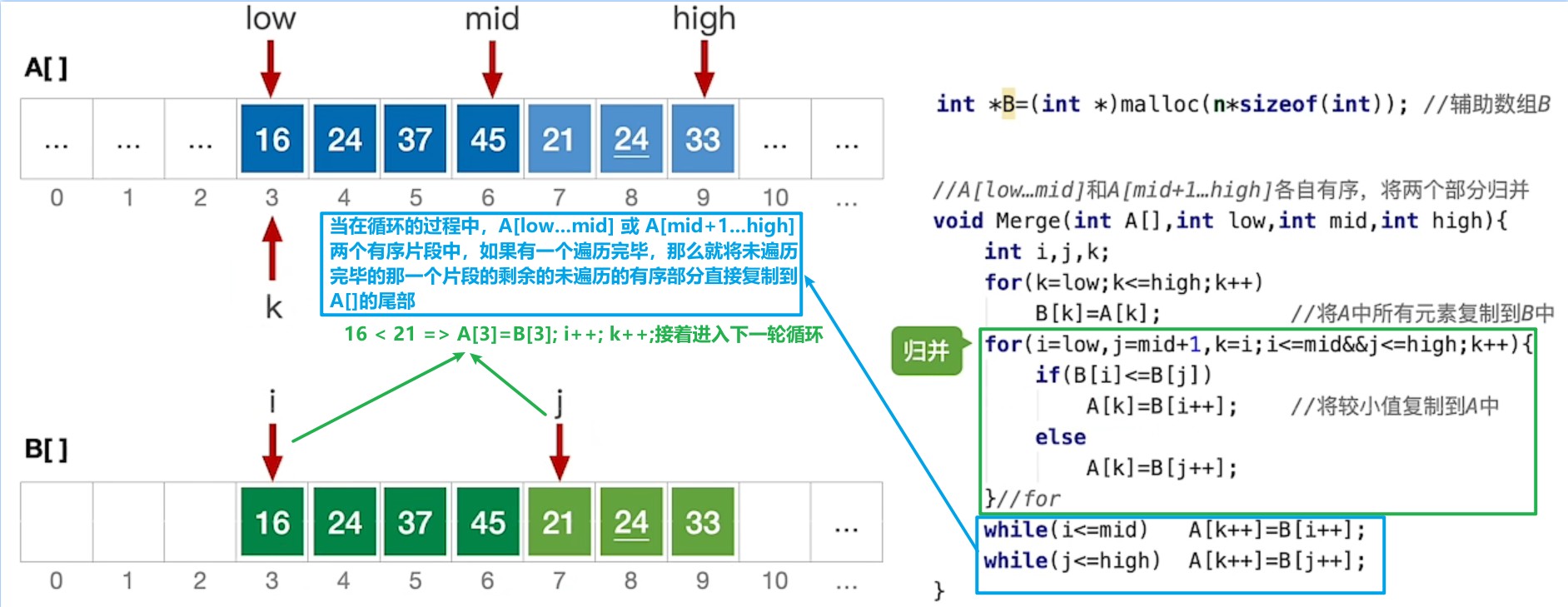
二路归并排序Merge归并部分具体代码的图文解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| #include<iostream>
#include<vector>
using namespace std;
void Merge(vector<int> &A, int low, int mid, int high) {
int i, j, k;
vector<int> B(A.size());
for(k = low; k <= high; k++) {
B[k] = A[k];
}
for(i = low, j = mid + 1, k = i; i <= mid && j <= high; k++) {
if(B[i] <= B[j]) {
A[k] = B[i++];
}else {
A[k] = B[j++];
}
}
while(i <= mid) A[k++] = B[i++];
while(j <= high) A[k++] = B[j++];
}
void MergeSort(vector<int> &A, int low, int high) {
if(low < high) {
int mid = (low + high) / 2;
MergeSort(A, low, mid);
MergeSort(A, mid + 1, high);
Merge(A, low, mid, high);
}
}
int main() {
int n;
cout << "请输入待排序序列中元素的个数:";
cin >> n;
vector<int> A(n);
cout << "请输入待排序序列:";
for(int i = 0; i < n; i++) {
cin >> A[i];
}
MergeSort(A, 0, n - 1);
for(int i = 0; i < A.size(); i++) {
cout << A[i] << " ";
}
return 0;
}
|
字符串匹配算法
KMP算法:
数据:1、待匹配的字符串(例如:googlogoogoogle) 2、模板字符串(例如:google)
思路:先通过模板字符串计算出next[]数组 (该例题的结果:next[] = {-1 0 0 0 1 0});然后通过这个next数组来在待匹配的字符串中 查找模板字符串的位置。(该例题的结果为:9)
优点:通过next[]数组来进行模板字符串的匹配,就可以减少很多不必要的字符比较,这样就大大的减少了算法所需要的时间
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| function get_next(next, t) {
let j, k;
let n = t.length;
next[0] = -1;
next[1] = 0;
for (let i = 2; i < n; i++) {
j = 1;
k = 0;
let tempj = j;
while (tempj < i) {
if (t[tempj] == t[k]) {
tempj++;
k++;
} else {
j++;
tempj = j;
k = 0;
}
}
next[i] = k;
}
}
function index_kmp(next, s, t) {
let i = 0,
j = 0;
let s_n = s.length;
let t_n = t.length;
while (i < s_n && j < t_n) {
if (j == -1 || s[i] == t[j]) {
j++;
i++;
} else {
j = next[j];
}
}
if (j >= t_n) {
return i - t_n;
} else {
return -1;
}
}
|
next[]数组的求法:

按照如上方法先求出next数组,然后通过next数组来确定下一次匹配时j的位置。

